


 摘要:
最近,语音AI这个赛道,又被OpenAI搞火了。就在9月25日,GPT-4o高级语音终于开始全量推出,Plus用户一周内都能用了。在OpenAI的移动端APP上即可体验!讲真,这是...
摘要:
最近,语音AI这个赛道,又被OpenAI搞火了。就在9月25日,GPT-4o高级语音终于开始全量推出,Plus用户一周内都能用了。在OpenAI的移动端APP上即可体验!讲真,这是... 最近,语音AI这个赛道,又被OpenAI搞火了。
就在9月25日,GPT-4o高级语音终于开始全量推出,Plus用户一周内都能用了。在OpenAI的移动端APP上即可体验!
讲真,这是AI渐冷的日子里,为数不多的“高光时刻”。
此外,还带上了一些更新,增加自定义指令、记忆、5种新的声音和改进的口音。与标准语音模式进行区分(黑色旋转球),高级语音将以蓝色旋转球表示。
并且,其中还包括对诸如重庆话、北京儿化音等地域性方言的精准模仿,可以说是学嘛像嘛。

在消除语音机械感的同时,用户不仅可以随时打断通话,即使不和它说话时,它也能保持安静,一旦有任何问题可随时向它提出。
从总体上来说,这次语音AI的更新,让GPT-4o的交互越来越有“人味”了。
不过,早在GPT-4o的实时语音功能推出前,国内的一批大厂,就已经率先开始了对语音AI这块高地的争夺,其焦点也是冲着“实时交流”“真人化”等方向去的。
至于结果…… 只能说,在“徒有其表”的模仿下,国内的语音AI,离真正通用且泛化的人机交互方式,还有相当一段距离。
Part.1 短板暴露
在AI时代,语音AI最大的意义是什么?
对于这个问题,科大讯飞给出了一个具有全局性的答案:
语音平台可能成为未来物联网的“操作系统”,换句话说,就是当物联网将所有的设备都能联网后,什么智能硬件、自动驾驶汽车、消费级机器人等等,都是潜在的应用场景。
到那时候,要想让这些设备能听懂人话,那就得靠语音平台了。
但是,虽然总的思路挺有格局的,但在具体实施的手段上,讯飞这样的大厂却走了一条“自下而上”的路线。

大体意思是,在语音AI生态的构建上,讯飞这几年基本上是从行业场景一个个往下打,像教育、医疗、政务这些场景,都是它们重点发力的地方。
从总体上看,讯飞的策略是先抓住这些垂直领域,通过提供专用解决方案来逐步累积数据和优化算法。这个做法有个好处,就是每个场景里,讯飞可以做得很深、很专。
举例来说,讯飞在2022年推出了“讯飞医疗AI医生助手”,这款产品能在病历记录、辅助诊疗等方面提供语音输入和智能建议,帮助医生减轻文书工作压力。

类似的例子,还有讯飞在2023年推出了“智慧课堂解决方案”,旨在通过语音识别和评测技术,帮助教师进行实时的课堂互动与教学反馈。
在这些垂直领域,星火的定制化方案,确实解决了很多行业痛点,也使得讯飞能够在激烈的市场竞争中保持行业的龙头地位。
在GPT-4o推出语音演示功能后,讯飞的星火大模型,也紧随其后,推出了同样能够极速响应、自由打断,且能在各种情感、风格、方言随意切换的语音AI。
然而,对于构建能够“统一调度”的大平台级别的语音AI来说,除了做到布局广,且“说话流畅”之外,还有至关重要的一步。
那就是:实时状态下的语音AI,究竟能否帮助用户解决一些较为复杂的需求?
关于这点,我们对讯飞的星火大模型进行了一次测试。
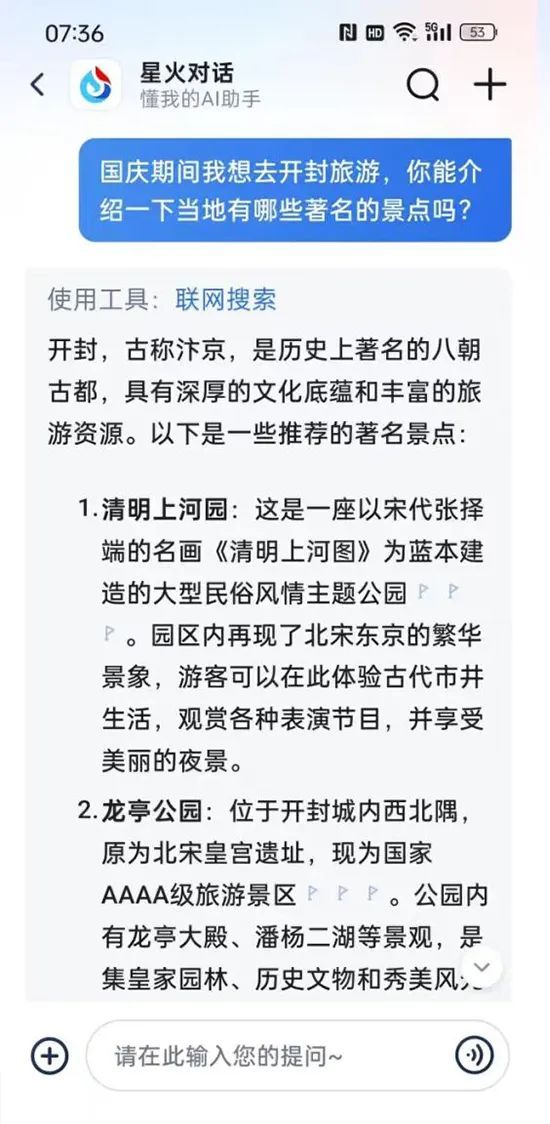
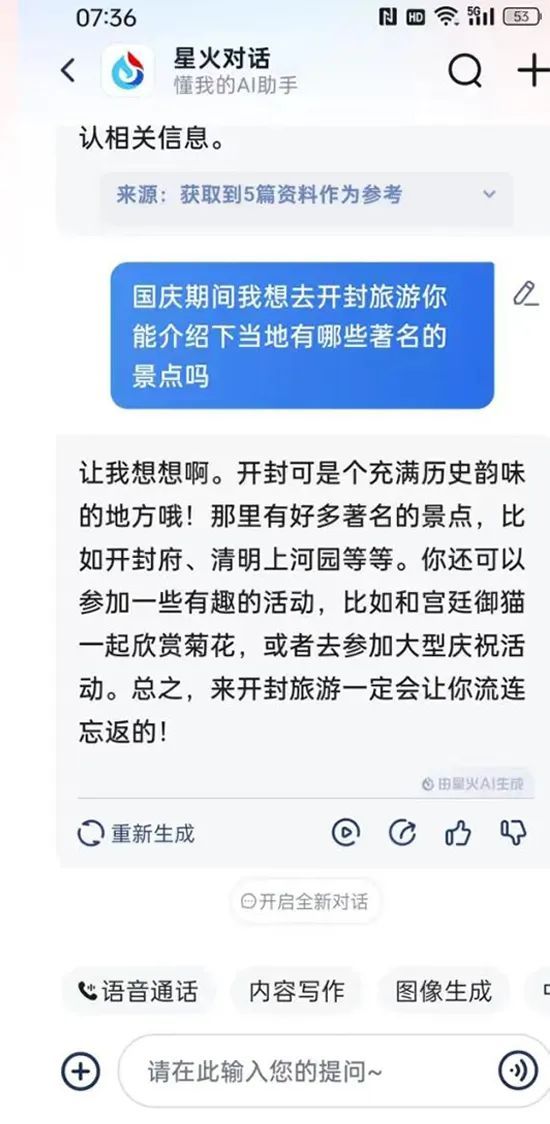
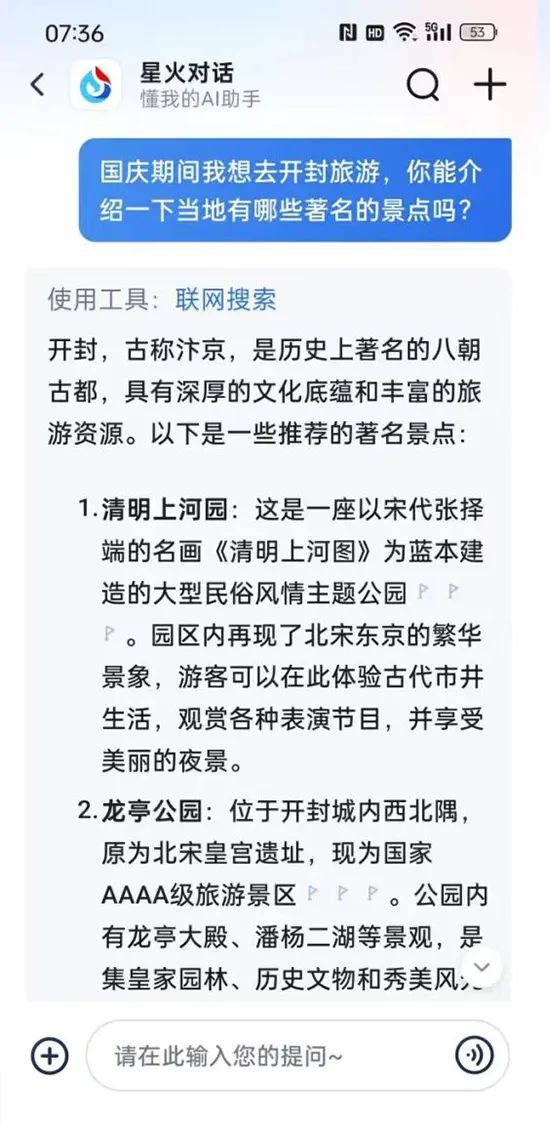
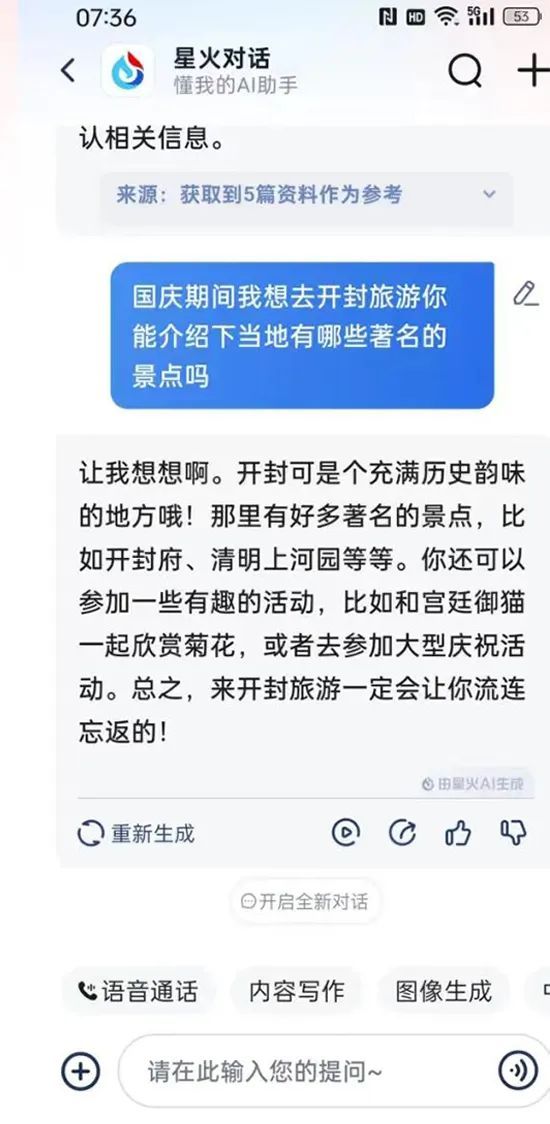
例如,在询问开封有哪些著名景点时,讯飞的实时语音AI,虽然回答得很流畅,但答案却较为简单,比纯文本状态下省略了很多内容。
那造成这种差距的关键原因是什么?
其实,对于GPT-4o这样的语音AI来说,除了确保通话流畅的RTC技术外,其背后还有一种关键的技术。
这就是端到端的语音大模型。
在以往的AI语音交互中,语音的处理大致分成了三个步骤。传统的 STT(语音识别,Speech-to-Text)-LLM(大模型语义分析)- TTS(文本到语音,Text To Speech)三步走的语音技术。
这样的技术,特点是成熟,但反应慢,缺乏对语气等关键信息的理解,无法做到真正的实时语音对话。
与过去的三步式语音交互产品相比,GPT-4o 是一款跨文本、视觉和音频端到端训练的新模型,这意味着所有输入和输出都由同一个神经网络处理。
这也是GPT-4o说话时反应贼快,智商还在线的重要原因。
而当今一众力图模仿GPT-4o的国产厂商,例如字节跳动,虽然依靠RTC技术,让语音AI做到了流畅、即时,但在最核心的“内功”,即端到端语音模型方面,却露出了短板。
Part.2 “智力”缩水
在今年的8月21日,字节挑动的豆包大模型,搭载了火山引擎的RTC技术,也实现了类似GPT-4o的实时音频互动表现,能够做到随时打断,交流自然,感觉就像真人说话一样。
所谓RTC(Real-Time Communication)技术,是一种支持实时语音、实时视频等互动的技术。旨在降低语音通话中的延迟,使得用户在进行语音对话时感觉更加自然和顺畅。
但RTC主要解决的,仅仅是语音AI流畅性和实时性问题,但它并不能直接整合语音识别、理解和生成的步骤。
换句话说,在实时通话时,模型虽然话说得利索了,但智商却不一定在线。
一个明显的例子,就是字节的豆包大模型,在通过实时语音AI与用户交流时,遇到了和讯飞星火一样的问题,那就是语音AI的智力,明显比纯文本大模型被“砍”了很多。
例如,在对《黑神话:悟空》这一话题进行交流时,纯文本状态下的豆包,回答明显要比实时语音的豆包要更详细,更有针对性。
一个可能的原因,是豆包在进行语音交互时,使用的并不是真正的端到端语音大模型。
在非端到端模型中,语音识别、理解和生成可能仍然是分开的步骤,模型需要在极短的时间内完成语音识别、理解和生成,而这一过程的计算和响应速度,会限制其对复杂问题的深入处理。
当模型被迫快速反应时,由于无法充分利用上下文信息,从而导致了“智力下降”的表现。

其实,真正的端到端语音大模型,实现起来远非想象中那么简单。
其中的难点,一在训练数据,二在计算资源;
根据腾讯算法工程师Marcus Chen的推测,GPT-4o这样的端到端语音大模型,背后使用的一种工程学方法,很可能是一种名叫离散化技术的路子。
这个技术,简单点说,就是把这些连续的声音波形切成一段一段的,每一段都提取出它特有的特征,比如语音的语义信息和声学特征。这些特征就像是一个个小的“口令”,机器可以把它们当成输入,丢到语言模型里去学习和理解。
但这可不是什么人人都能轻松掌握的技术。
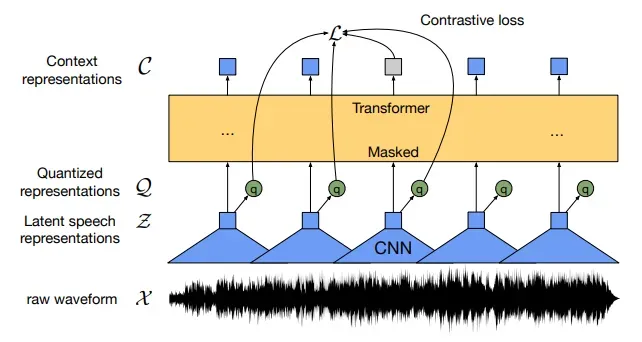
要想做出高质量的语音token,需要大量的数据积累和复杂的建模过程。
这样的高质量数据,往往来自高质量的视频、播客等等。成本是过去文字训练模型的几十倍甚至更高。
而在计算资源方面,在实时互动场景中,计算必须在极短的时间内完成,这意味着端到端的大模型,通常需要消耗大量的计算资源,尤其是在处理高维度的语音数据任务时。
这也是为什么,OpenAI在推出GPT-4o的语音AI功能后,对用户的使用量进行了额度限制。其额度消耗和GPT-4o回复的额度一样。
反观现在以豆包为首的一些国产语音AI,虽然以免费、不限次数为噱头,但其生成质量,却相较于纯文本状态大打折扣。
这或许正是在算力资源紧张的情况下,模型采取的一种“权宜之计”。
因为当计算资源不足时,模型可能会优先选择简单的、低耗能的响应方式,以确保能够及时回应用户的请求。
毕竟,又想要免费无限地使用,又想要高质量的实时回复,天底下哪有那么好的事?
Part.3 算力困境
在AI时代,各类To C 语音产品的主要逻辑是,将昂贵或难以获得的人类服务,且是基于对话且可以在线完成的,替换为 AI,主要场景包括心理疗愈、辅导、陪伴等。
对于To C 类APP,要想大范围地落地,其中一个前置条件,必然是成本的大幅度降低。唯有如此,企业才能够以更低的价格提供服务,进而不断扩大用户基数。
但问题是,在降低成本的同时,质量和成效能否保障一定的水准?
这正是最考验讯飞、字节等大厂的一点。
从商业上来说,在降低成本的同时,要想质量不拉胯,就需要有源源不断的资金,进行研发和技术迭代。
这就要求企业找到一种明确的商业模式,来自我造血。
OpenAI之所以能在如此短的时间推出GPT-4o的语音功能,是因为背靠微软,能获得源源不断的融资,从而不断强化其模型的能力。
相较之下,坐拥几乎是行业内最为丰富业务场景的科大讯飞,虽然赶上了2023年AI浪潮,并在同年6月市值一度逼近2000亿大关,可随着其大模型持续高额的投入、销售费用持续攀升。当下,讯飞对大模型收益能否覆盖成本尚无定论,成本压力始终存在。

一个重要的问题是:既然在一些特定的行业,例如医疗、教育、客服等,传统语音AI已经能够胜任了,那么以端到端大模型为核心的语音AI,又该怎样从中获取自己的市场份额?
一个可能的方向,就是在各种长尾需求中,对一系列复杂查询和非标准化指令做出回应。例如在智能汽车或移动应用中,端到端模型可以通过自然语言,理解用户说的犄角旮旯的地点在哪,并提供精确的导航指令。
然而,在这种模式下,用户更多地是为语音AI背后强大的语言模型付费,为其出众的智力付费。
因此,端到端语音AI的盈利之路,一开始就因为这种“附属地位”而充满了坎坷,因为前者的能力一旦遇到瓶颈,其也会跟着“一损俱损”。
而在附属于语言大模型的尴尬之下,在算力资源的分配方面,语音AI也面临着一种不利的态势。例如,对于字节来说,迄今为止,字节跳动已经推出了11款AI应用;其中,豆包是国内用户最多的AI独立应用,其MAU可能已达到2000万量级。
然而,从业务布局上来说,语音AI现阶段不太可能是字节的重点。
在9月24日的深圳AI创新巡展上,火山引擎发布两款视频生成大模型PixelDance(像素舞动)和Seaweed(海草),很多业内人士分析,这条视频AI的类“Sora”赛道,才是以短视频闻名的字节真正不能输掉的一仗。
而AI视频生成,恰恰又是最消耗算力的一条赛道。

来源:豆包AI视频生成模型
与语音AI相比,同样消耗高算力的视频生成AI,因为对应着短视频这个更明确,且更易于盈利的赛道,因此在资源分配上,更有可能得到大厂或投资者的倾斜。
结合之前豆包在实时通话状态下的智力表现,我们或许能够推断,留给豆包打造端到端语音大模型的算力,未必会那么充足。
而这种资源不足,却又要在面上与GPT-4o一较高下的情况,这正是当下实时语音AI这支“偏军”在中国AI版图中的窘境所在。
语音交互技术火热了十来年,到了大模型时代,OpenAI、科大讯飞、字节这些大厂,又开始重新在往这领域挤,为何?因为这种技术,实际上暗藏着语音平台可能成为未来物联网“大脑”的想象。
通过一个语音平台,操控所有智能终端,这是所有传统语音AI都办不到的事。但是,这技术要想做得好,得先解决一个大问题,就是机器得能真正理解人说的话。这就需要AI在自然语言理解、知识获取这些领域有新的突破。
然而,在语言大模型遇到瓶颈,且算力资源被视频AI等“光环”更耀眼的产品抢走的情况下,语音AI在中国人工智能的版图中,暂且只能是个尴尬的存在。










还没有评论,来说两句吧...